|
I am a Ph.D. student at the AIEM lab, Johns Hopkins University in the department of Computer Science. I am advised by Prof. Rama Chellappa working on problems in Computer Vision and Deep Learning. My research has two focus points - general-purpose vision language models, where I work on multimodal LLMs on tasks like VQA, Video Grounding and LLM interpretability; and on fine-grained computer vision problems, where I work on person re-identification and gait recognition. I am supported by an IARPA grant, BRIAR. I have also worked on a DARPA grant, ANSR. Previously, I obtained a B.E. in Computer Science from Birla Institute of Technology and Science (BITS), Pilani. At BITS Pilani I was working under the guidance of Prof. Poonam Goyal on video captioning, and collaborating with Dr. Yogesh S Rawat from UCF on Gait Recognition. |

|
|
|
|
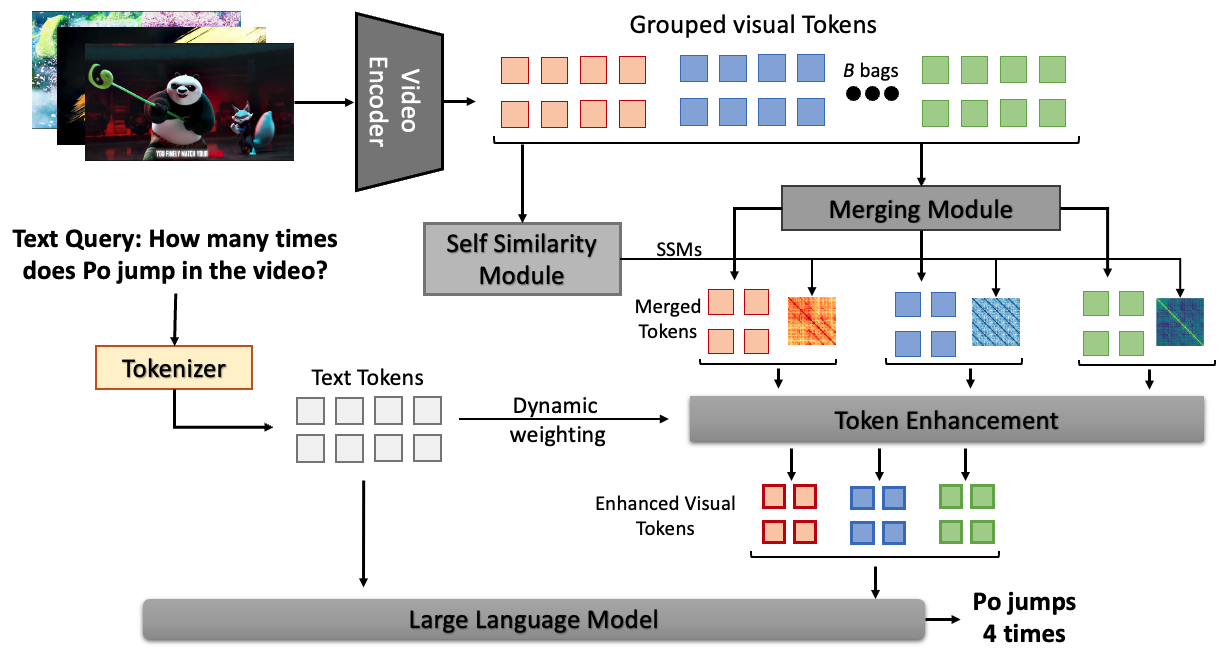
|
Ayush Gupta, Yan Li, Srinivas Parthasarthy, Jim Thomas under submission We enhance the video counting abilities of multimodal LLMs through a self-similarity based approach. Part of my Amazon Internship. More details coming soon! |
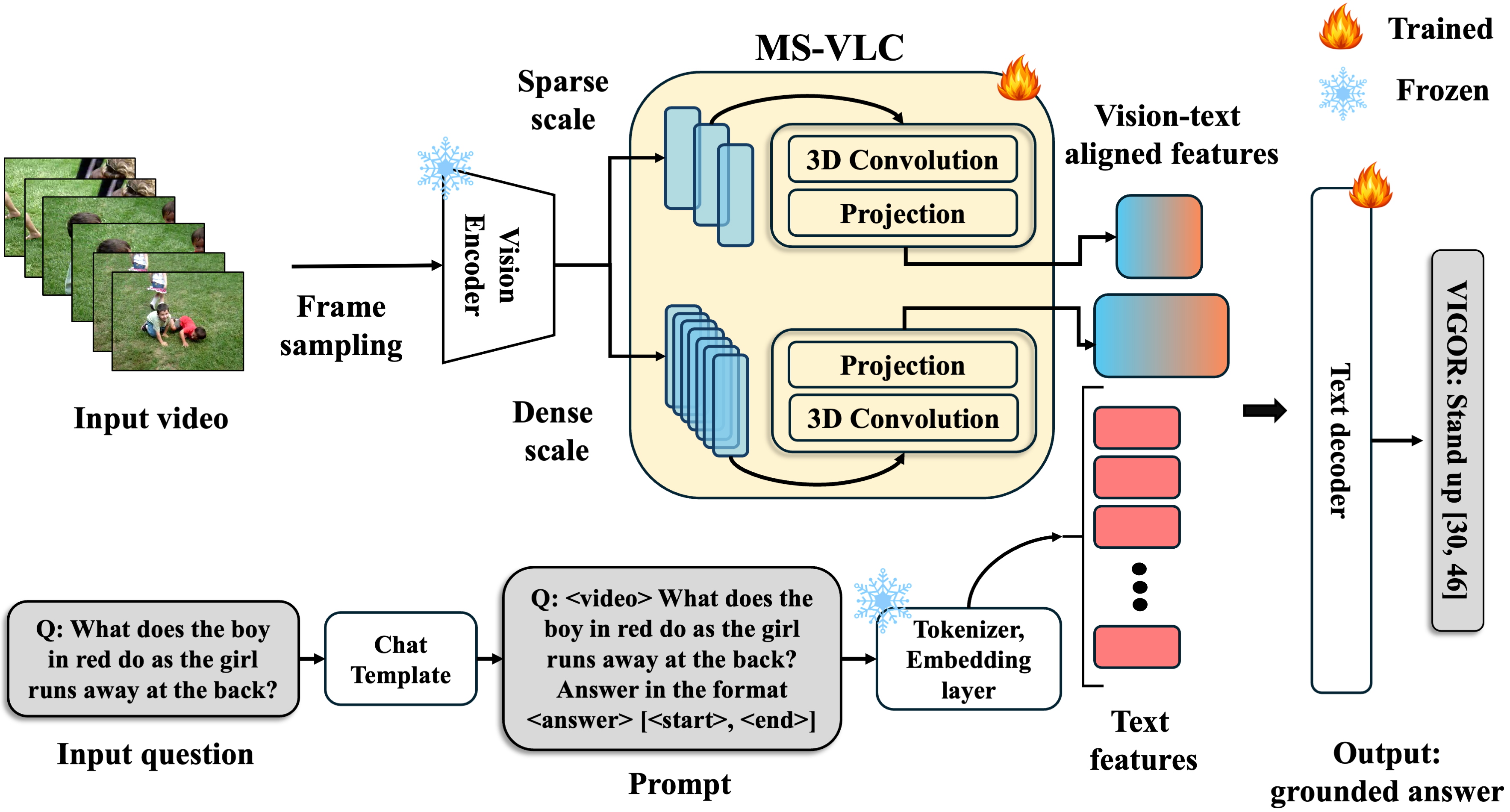
|
Ayush Gupta, Anirban Roy, Rama Chellappa, Nathaniel D. Bastian, Alvaro Velasquez, Susmit Jha ICCV 2025 We use multimodal LLMs for temporal grounding of question-answer pairs in unconstrained videos. Project Website / arXiv |
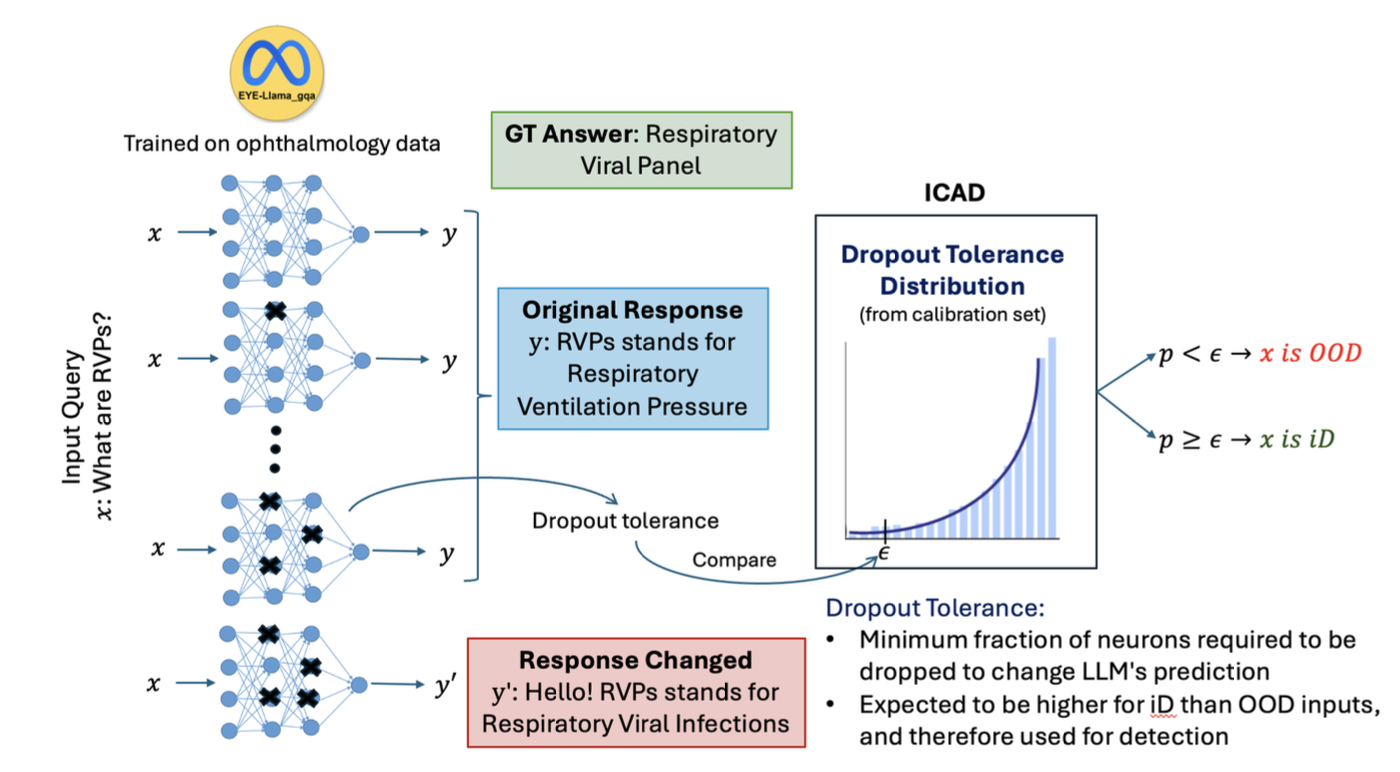
|
Ayush Gupta, Ramneet Kaur, Anirban Roy, Adam D. Cobb, Rama Chellappa, Susmit Jha EMNLP 2025 (main conference) We propose an inference time method to automatically detect out of distribution inputs, and predict the output uncertainity in specialized LLMs. Project Website / arXiv |
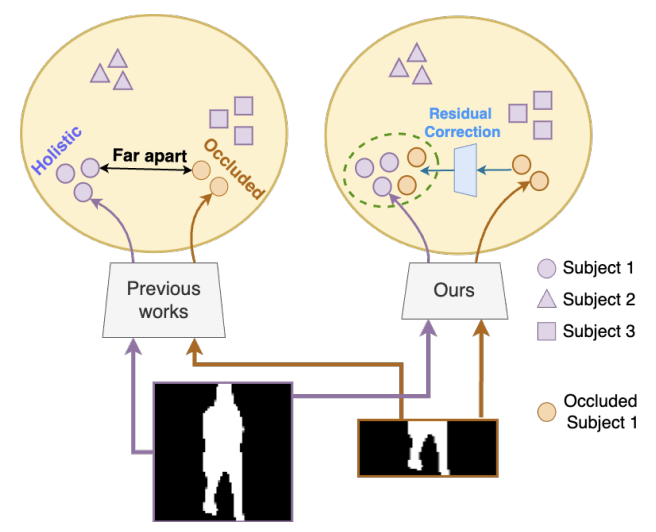
|
Ayush Gupta, Siyuan Huang, Rama Chellappa IJCB 2025 (oral) We employ Residual Correction for recovering complete features from occluded gait sequences. Project Website / arXiv |
|
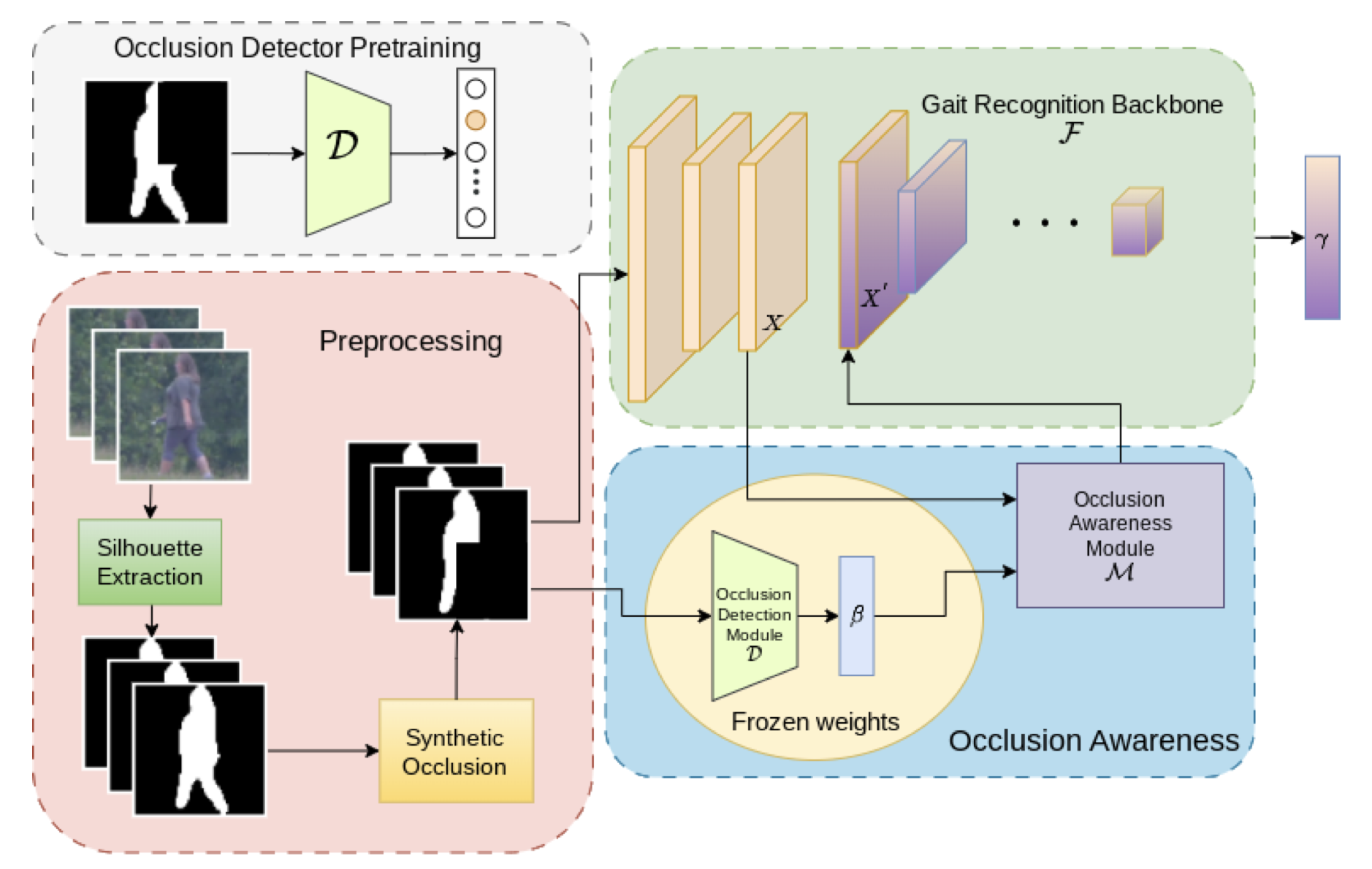
Ayush Gupta, Rama Chellappa WACV 2024 (oral) We use an auxiliary occlusion detector to solve the occlusion problem in long range gait recognition. Project Website / arXiv |
|
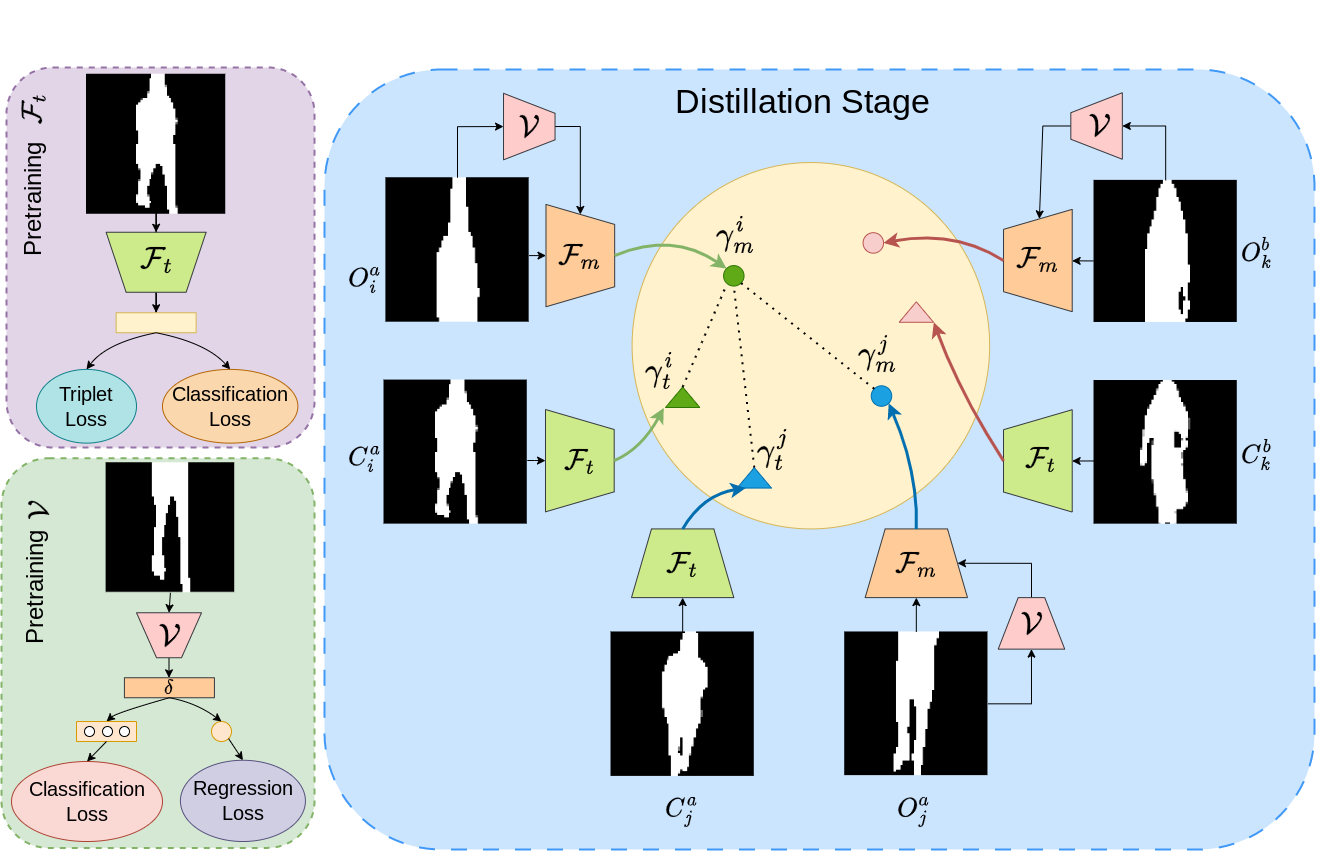
Ayush Gupta, Rama Chellappa WACV 2025 We tackle the occlusion problem in gait recognition using correlational knowledge distillation. Project Website / arXiv |
|
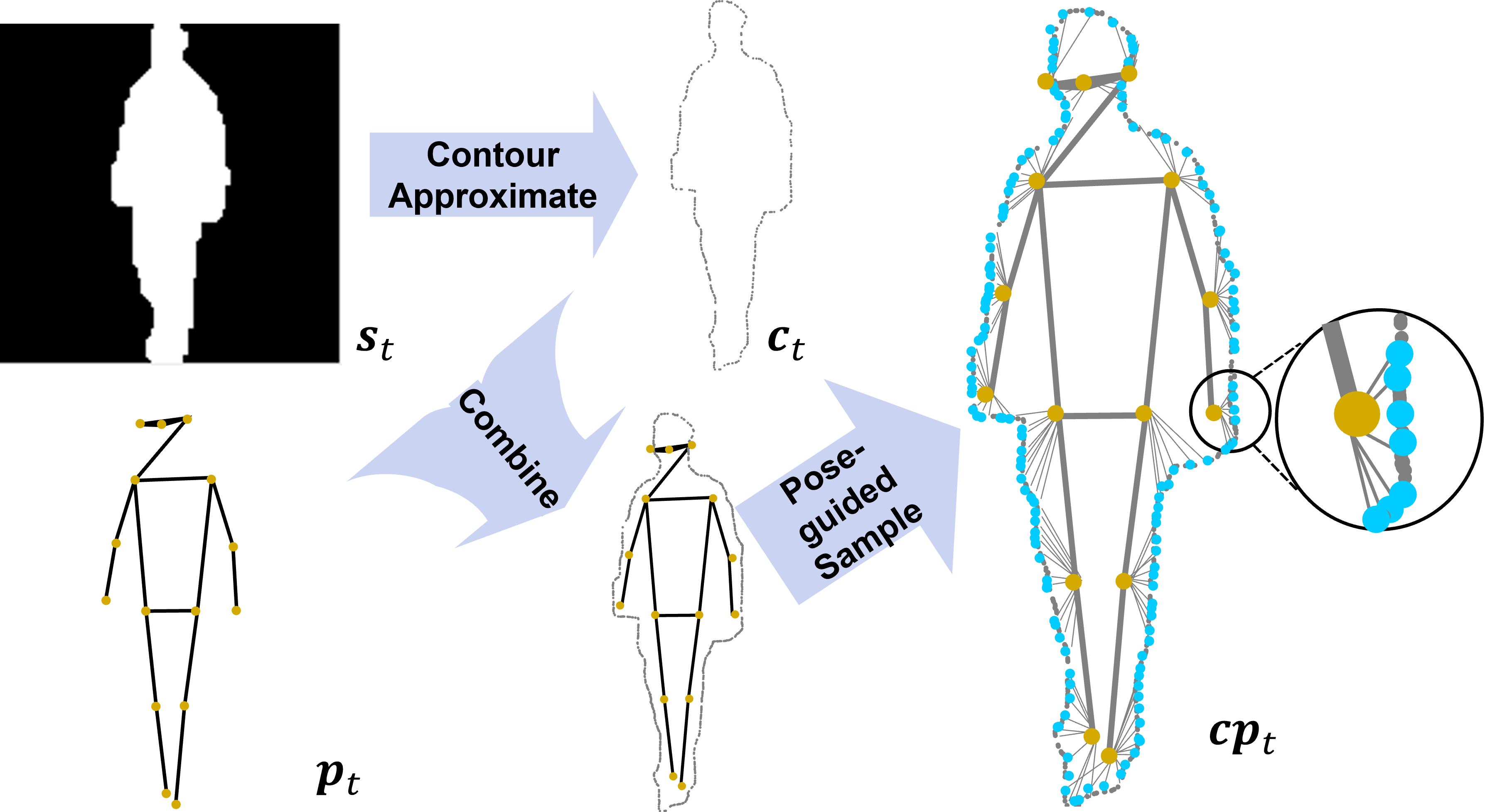
Yuxiang Guo, Anshul Shah, Jiang Liu, Ayush Gupta, Cheng Peng, Rama Chellappa WACV 2025 We develop a novel, efficient contour-based representation for gait recognition. arXiv |
|
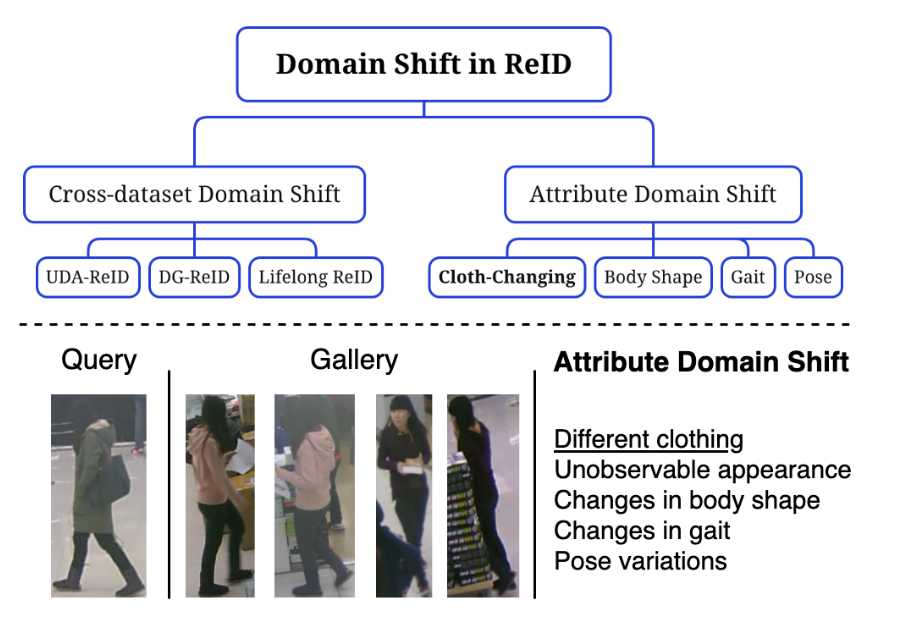
Vuong Nguyen, Samiha Mirza, Abdollah Zakeri, Ayush Gupta, Rahma Aloui, Khadija Khaldi, Pranav Mantini, Shishir Shah, Fatima Merchant CVPR 2024 Continual Learning Workshop A comprehensive survey on domain shift in Person Re-ID. We evaluate existing methods under various settings and give directions for future research. Paper |

|
Laura McDaniel, Ayush Gupta, Ime Essien, Ryan Roemmich, Peter Abadir, Rama Chellappa under submission Using computer vision techniques to diagnose frailty among older adults. |
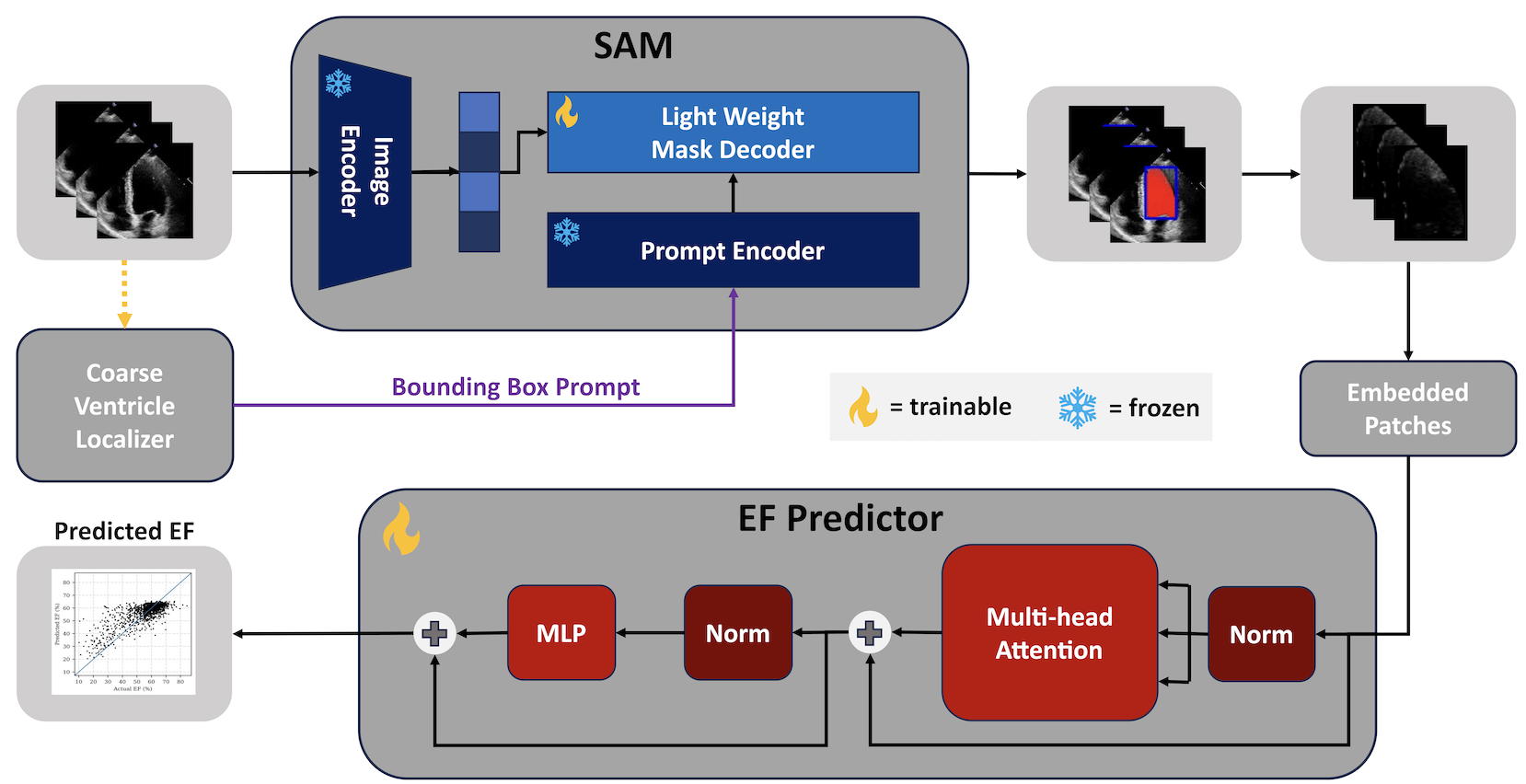
|
Basudha Pal, Ayush Gupta ,Vishal Patel Predicting the Ejection Fraction from ultrasound images of the heart, utilizing the Segment Anything Model. |

|
Ayush Gupta, Alexander Matasa, Shruti Vyas, Yogesh S Rawat Developing a novel technique for unsupervised gait recognition using temporal self similarity. |

|
Ayush Gupta*, Ashrya Agrawal*, Poonam Goyal, Navneet Goyal An approach for generating natural language captions of videos using external knowledge bases. Paper |
|
|